

Cassandra Monitoring Tools Comparison 2026
Teams comparing Cassandra monitoring tools are usually choosing between operating models, not just products. One path is the self-managed stack built from JMX Exporter, node_exporter, Prometheus, Grafana, and Loki. Another is to standardize on a managed observability platform such as Datadog, Dynatrace, or Grafana Cloud. Both can work. The real question is how much Cassandra context you get before the monitoring platform becomes another engineering project to own.
AxonOps is included here because it approaches monitoring from the Cassandra side rather than from the generic observability side. That makes it useful in this comparison as a reference point for what deeper Cassandra-specific metrics, operational context, and alerting workflows can look like.
If you want to see that monitoring surface directly, the AxonOps Apache Cassandra monitoring feature page shows how metrics, logs, service checks, and alert routing are presented in the product.
For this article, the self-managed option is treated as one stack because that is how Cassandra teams deploy it in practice. Where a feature is marked as custom, it means the outcome is achievable but not delivered as a documented Cassandra workflow out of the box.
What Cassandra teams need
For Cassandra teams, the basic question is not whether a tool can draw charts. Almost every product in this comparison can do that. The useful questions are whether it understands Cassandra as a database platform, whether it can alert on operational events beyond raw metrics, and whether it lets you route alerts with enough context that the right team can act quickly.
That usually comes down to five areas. First, you need broad metric coverage across Cassandra, the JVM, and the host. Second, you need logs and service checks in the same operational view. Third, you need rules that can cover node failures, saturation, security events, stalled repairs, and failed backups. Fourth, you need alert routing that can follow cluster, datacenter, severity, and domain boundaries. Finally, you need all of this without turning observability itself into a full-time platform project. The comparison below reflects documented, out-of-the-box capabilities as of March 12, 2026.
Platform coverage
| Capability | AxonOps | Self-managed stack JMX Exporter + node_exporter + Prometheus + Grafana + Loki |
Datadog | Dynatrace | Grafana Cloud |
|---|---|---|---|---|---|
| Cassandra-native monitoring model | ✓ Full Built around Cassandra clusters, nodes, service checks, repairs, backups, and operational history. |
✗ No Flexible components, but Cassandra context is something you assemble yourself. |
◐ Integration-led Strong integration model, but Cassandra remains one integration among many. |
◐ Extension-led Strong platform-wide correlation, but Cassandra is extension-led rather than domain-led. |
◐ Managed open stack Managed Prometheus, Loki, and Grafana service, but Cassandra still depends on JMX Exporter, Alloy, labels, and dashboards you manage. |
| Cassandra metrics depth | ✓ Full Cassandra, JVM, table, keyspace, coordinator, replica, and infrastructure metrics at 5-second resolution. |
◐ Good Depends on exporter configuration, scrape design, and the dashboards you build. |
◐ Good Datadog's built-in Cassandra Agent check can be pushed beyond the default set, but broader JMX coverage still sits inside Datadog's generic model and can drive up billable custom-metric volume. |
◐ Good Cassandra visibility comes through the extension and broader Dynatrace telemetry. |
◐ Good The Cassandra integration covers cluster, node, and keyspace metrics, but deeper table-level coverage still means extra JMX mapping and more active series. |
| Metrics collection resolution | ✓ 5 seconds High-resolution collection is practical because the collector is designed to stay low profile. |
◐ Configurable Prometheus scrape interval is flexible, but tighter intervals increase Cassandra JVM CPU pressure when JMX Exporter is scraping a large metric surface, and also raise exporter and storage cost. |
◐ Varies by Datadog setup Collection cadence depends on the Datadog configuration, but Datadog bills custom metrics by distinct timeseries rather than submission frequency. |
◐ 1-minute custom metric resolution Dynatrace states that custom metrics ingestion uses a standard 1-minute resolution. |
◐ Configurable Prometheus-style scrape intervals are flexible, but higher-resolution JMX scraping still increases Cassandra JVM overhead and the number of active series sent to Grafana Cloud. |
| Documented default Cassandra scope | ✓ Deep by default Table metrics, threadpools, consistency-level views, and Cassandra operations are part of the normal product surface. |
◐ Whatever you model Depth depends on exporter rules, scrape design, and the dashboards and alerts you maintain. |
◐ 350 metrics per instance Datadog documents a standard limit for the Cassandra Agent check and directs teams to customize or contact support if they need more. |
◐ 28 default custom metrics per process Dynatrace documents 28 default Cassandra JMX metrics per process and a 5,000-metric limit per JMX extension. |
◐ 8 alerts + 3 dashboards Grafana Cloud documents 8 useful alerts, 3 pre-built dashboards, and cluster, node, and keyspace metrics and logs for Cassandra. |
| Primary Cassandra metric collection path | ✓ Bespoke Java collector Bulk Cassandra metric collection bypasses the JMX layer. |
✓ JMX Exporter Cassandra metrics are exposed through JMX and scraped by Prometheus. |
◐ JMX-based Agent check Datadog's built-in Cassandra Agent check uses a JMX collection path, with a separate nodetool check available for extra cluster data. |
◐ OneAgent + Cassandra JMX extension Dynatrace documents Cassandra monitoring through its Cassandra JMX extension. |
◐ Grafana Alloy + JMX Exporter Grafana Cloud documents Cassandra monitoring through JMX Exporter on each node, scraped by Grafana Alloy. |
| Node and infrastructure metrics | ✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes |
| Metrics, logs, and Cassandra operational context together | ✓ Full Metrics, logs, service checks, configuration, repairs, backups, and nodetool events in one operational surface. |
◐ Possible Prometheus, Grafana, and Loki can be linked, but you design the labels, dashboards, and drill-downs. |
◐ Metrics + logs Metrics and logs are strong; Cassandra operational workflows still need custom modelling. |
◐ Cross-stack correlation Good cross-stack correlation, but Cassandra-specific operational domains are not first-class. |
◐ Metrics + logs Prometheus metrics and Loki logs can be correlated in one managed stack, though Cassandra operational domains still remain custom work. |
| Configuration visibility | ✓ Full Cassandra, JVM, and OS configuration tracked per node. |
✗ No Needs extra tooling or custom collection. |
✗ Not documented out of the box Datadog's Cassandra Agent check documents JMX metrics and logs, not cassandra.yaml, JVM config, or kernel tuning visibility. |
✗ Not documented out of the box The Apache Cassandra extension documents JMX metrics, logs, and process analysis, not Cassandra yaml, JVM config, or kernel tuning visibility. |
✗ Not documented out of the box Grafana Cloud documents Cassandra metrics and logs through JMX Exporter and Alloy, not Cassandra yaml, JVM configuration, or OS kernel tuning visibility. |
| Service checks for Cassandra availability | ✓ Full Node reachability, CQL, JMX, and flexible custom checks configured server-side with no agent-side changes. |
◐ Custom Achievable, but you need extra jobs and alert logic. |
◐ Host and service checks General service and host checks are available, but not Cassandra-native by default. |
◐ Platform health monitoring Broad health monitoring is strong, though Cassandra service checks are not modeled natively. |
◐ Custom Possible through Prometheus targets, Loki queries, and Grafana Alerting, but not as a Cassandra-native service-check workflow. |
| Repair monitoring | ✓ Yes Real-time progress, full history, and failure alerting. |
✗ Not documented out of the box | ✗ Not documented out of the box | ✗ Not documented out of the box | ✗ Not documented out of the box |
| Backup monitoring | ✓ Yes Execution history, status, duration, and failure alerting. |
✗ Not documented out of the box | ✗ Not documented out of the box | ✗ Not documented out of the box | ✗ Not documented out of the box |
| PromQL-style open query access | ✓ Yes PromQL-compatible API for dashboards and external tooling. |
✓ Yes | ✗ No | ✗ No | ✓ Yes Managed Prometheus and Mimir keep the PromQL query model. |
| Agent overhead | Low Bespoke Java collector designed to stay low profile by bypassing the JMX layer for bulk metric collection. |
High Cassandra metrics are collected through JMX Exporter, so deep coverage still inherits JMX scraping cost, and with larger table counts the Cassandra JVM can show significant CPU spikes while that larger metric surface is being scraped. |
High Datadog's built-in Cassandra Agent check is JMX-based, documents a standard limit of 350 metrics per instance, and broader coverage means more JMX surface, more billable custom-metric timeseries, and more Cassandra JVM CPU pressure as table counts rise. |
High Dynatrace documents Cassandra monitoring through a Cassandra JMX extension, so the collection path still depends on JMX exposure and the associated cost of pulling a large metric surface, including Cassandra JVM CPU spikes once table-heavy estates are scraped deeply. |
High Grafana Cloud's Cassandra path still depends on JMX Exporter on each node, so deeper table coverage means more JMX scrape pressure, more active series, and more Cassandra JVM CPU cost as estates grow. |
Self-managed stack
The self-managed route still suits teams that already run Prometheus and Grafana well and want full control. The trade-off is that you own JMX Exporter, node_exporter, Loki, Alertmanager, dashboards, retention, and service-check plumbing, and once table count grows the Cassandra JVM can show real CPU spikes during deep JMX scrapes.
For a closer look at that trade-off, see Monitoring Cassandra: The Cost of Collecting Metrics.
Managed observability platforms
Datadog and Dynatrace are broad observability platforms. Grafana Cloud is closer to a managed Prometheus, Grafana, and Loki stack. All three can monitor Cassandra, but deeper table-level coverage still means more JMX mapping, more engineering work, more spend, and more Cassandra JVM CPU pressure during collection.
What deeper Cassandra visibility can look like
Cassandra itself exposes a large table-level and coordinator metric surface, including 67 table-level metric series before any consistency-level breakout, plus coordinator metrics across consistency levels and percentiles. The practical difference between tools is how much of that surface they collect, model, and make usable alongside service checks and operational context. When that depth is collected through a low-profile path instead of large JMX scrapes, it becomes practical to use in production without introducing the Cassandra JVM CPU spikes that often show up in table-heavy estates.
That difference shows up quickly in operations because Cassandra issues are often specific to one consistency path and one part of the latency distribution. Being able to filter coordinator metrics by consistency level and percentile means teams can isolate whether a problem is affecting LOCAL_QUORUM, ONE, or another consistency mode, and whether the issue lives in the tail rather than in the average.
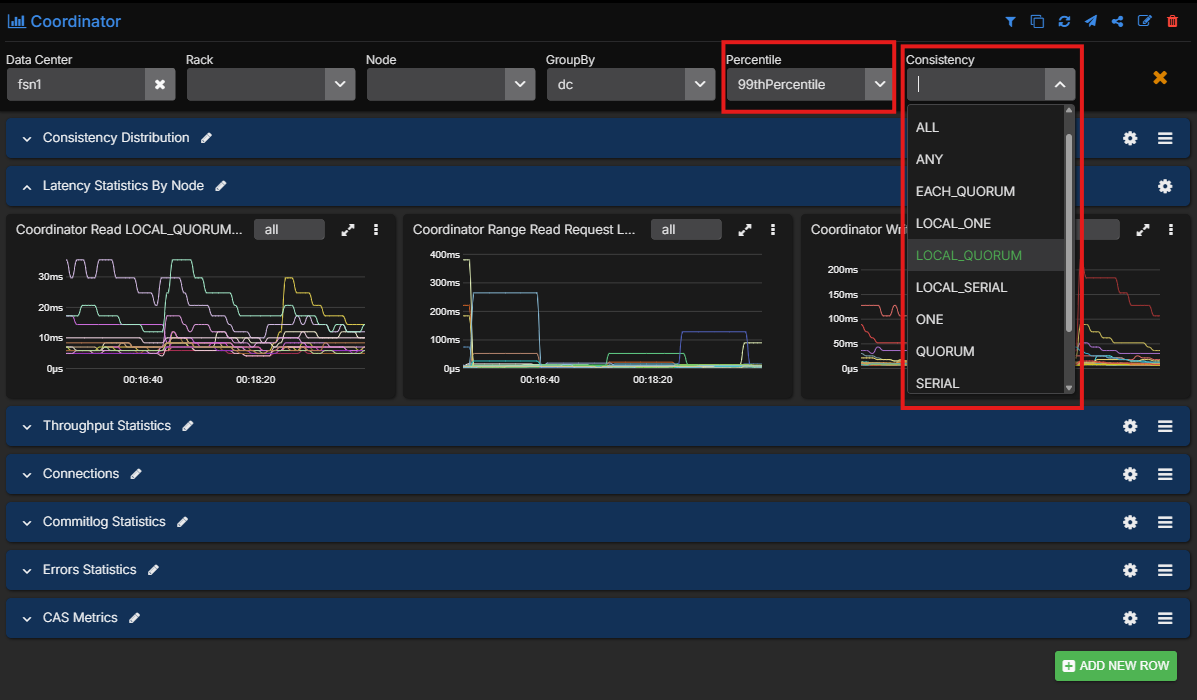
The same applies at table level. Operators can filter down to the exact tables involved instead of staring at keyspace or cluster-wide aggregates and trying to infer where the problem lives.
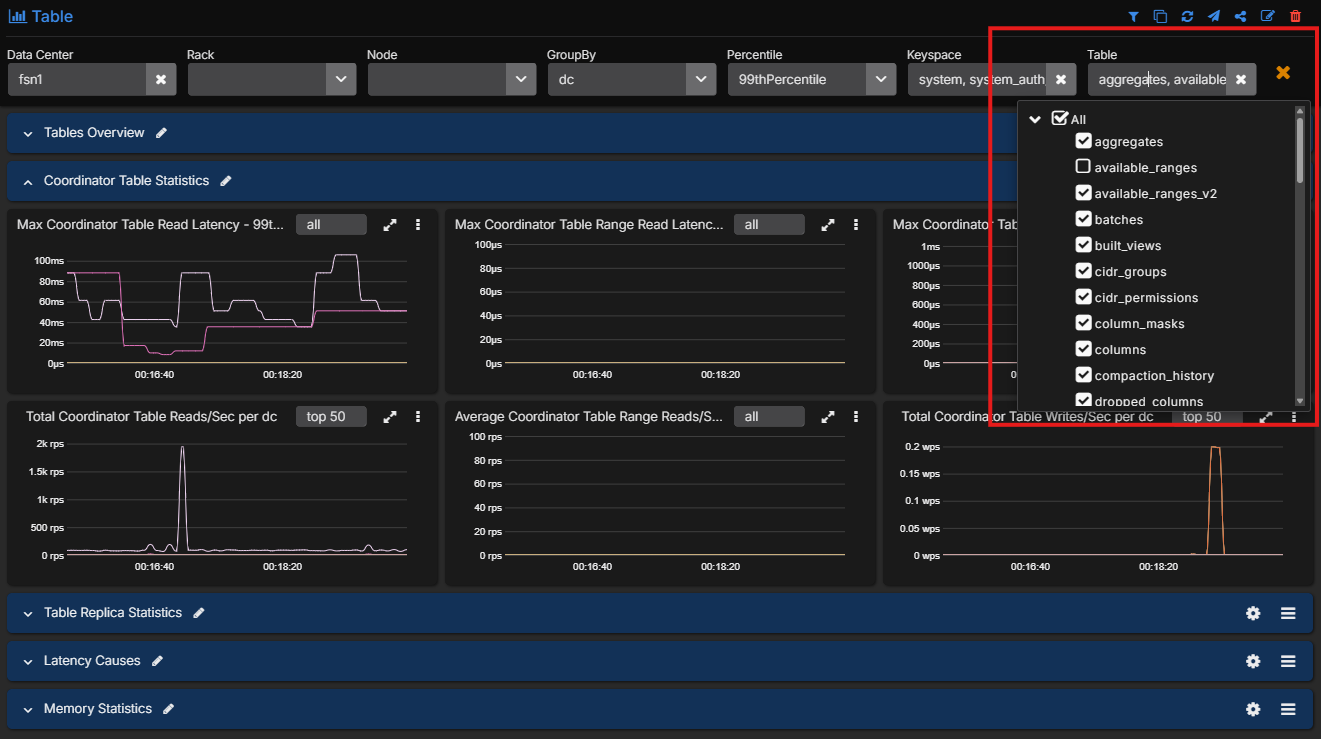
That is also the difference between generic observability and a dedicated Cassandra monitoring workflow. The AxonOps Cassandra monitoring page gives a fuller view of the metrics, logs, service checks, and alerting model behind these screenshots.
Resolution comparison
The charts below show the same short-lived spike rendered at 5-second, 30-second, and 60-second resolutions. This is the practical difference behind the resolution row in the table. At 5 seconds, the spike is obvious. By 30 seconds it is already smoothed. By 60 seconds, short-lived behavior is materially flattened.
The bigger issue is not only short-lived spikes. Platforms that depend on JMX scraping force teams into an ugly trade-off. If you scrape at high resolution and include the threadpools, table metrics, and other Cassandra detail you actually need, the Cassandra JVM starts paying for it. If you back off the scrape depth or the resolution to keep overhead tolerable, you lose the instrumentation that tells you which table, which threadpool, or which consistency path is actually in trouble. That is why many enterprise teams end up operating Cassandra like a commercial aircraft with an incomplete instrument panel. They can tell something is wrong, but they do not have all the readings they need to pinpoint the fault quickly.
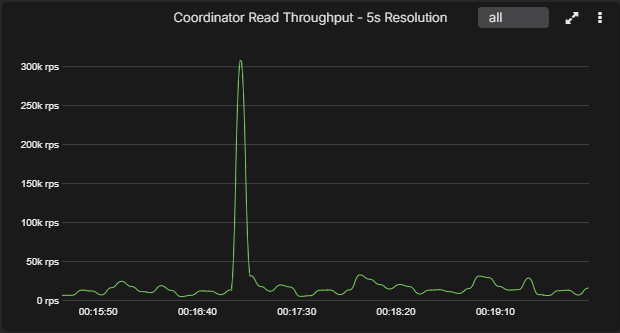
5-second resolution
A short, sharp coordinator throughput spike is preserved with its real peak and duration intact.
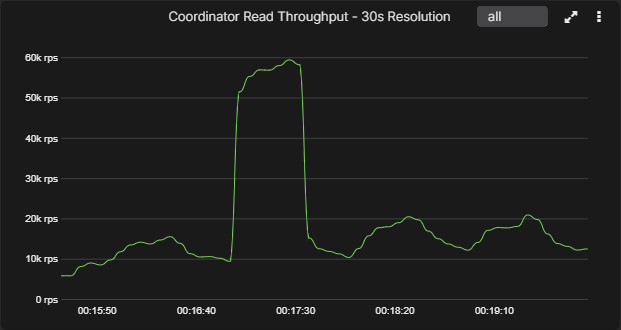
30-second resolution
The same event is already smeared into a much wider plateau, which changes how severe it looks.
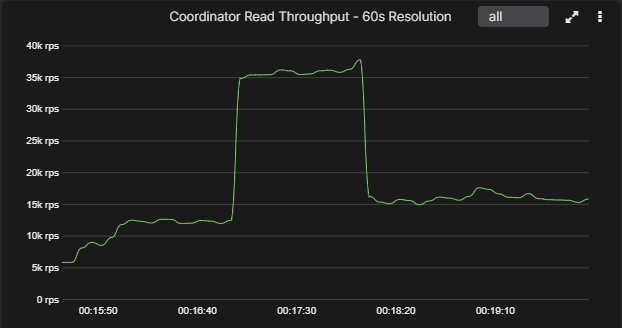
60-second resolution
By 60 seconds, the narrow spike has turned into a broad block and the real peak is largely hidden.
Cassandra metric coverage detail
This is where the difference between a Cassandra-native platform and a generic observability stack becomes concrete. The question is not whether a platform can ingest JMX somewhere. The question is whether the Cassandra metrics you actually care about arrive ready to use, with the right dimensionality and percentile coverage, instead of becoming a custom exporter and dashboard project. For many teams, that is the difference between operating with real instrumentation and operating half-blind.
| Metric or metric family | AxonOps | Self-managed stack | Datadog | Dynatrace | Grafana Cloud |
|---|---|---|---|---|---|
| System / OS | |||||
| OS and node metrics | ✓ Native CPU, memory, disk I/O, filesystem, and network throughput in the same platform. |
✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes |
| JVM internals | ✓ Native Heap, GC, threads, buffers, and JVM process health. |
✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes |
| Coordinator | |||||
| Coordinator throughput per table | ✓ Native | ◐ Possible Requires JMX exporter rules and dashboard work. |
◐ Possible via Datadog Cassandra Agent check | ◐ Possible via Dynatrace Cassandra JMX extension | ◐ Possible with custom JMX Exporter rules |
| Coordinator latency percentiles per table | ✓ Native All percentiles. |
◐ Possible Depends on MBean exposure, mapping, and dashboard design. |
◐ Possible with extra JMX mapping | ◐ Possible with JMX extension customization | ◐ Possible with custom JMX Exporter rules |
| Coordinator metrics by consistency level | ✓ Native All consistency levels and all percentiles. |
◐ Possible Usually custom mapping and dashboarding. |
◐ Not documented out of the box | ◐ Not documented out of the box | ◐ Not documented out of the box |
| Table metrics | |||||
| Replica throughput per table | ✓ Native | ◐ Possible | ◐ Possible via Datadog Cassandra Agent check | ◐ Possible via Dynatrace Cassandra JMX extension | ◐ Possible with custom JMX Exporter rules |
| Replica latency percentiles per table | ✓ Native All percentiles. |
◐ Possible | ◐ Possible with extra JMX mapping | ◐ Possible with JMX extension customization | ◐ Possible with custom JMX Exporter rules |
| Estimated partition count | ✓ Native | ◐ Possible | ◐ Possible via Datadog Cassandra Agent check | ◐ Possible via Dynatrace Cassandra JMX extension | ◐ Possible with custom JMX Exporter rules |
| Max table partition size | ✓ Native | ◐ Possible | ◐ Not documented out of the box | ◐ Not documented out of the box | ◐ Not documented out of the box |
| Mean partition size | ✓ Native | ◐ Possible | ◐ Not documented out of the box | ◐ Not documented out of the box | ◐ Not documented out of the box |
| Tombstones scanned percentiles | ✓ Native All percentiles. |
◐ Possible | ◐ Possible with extra JMX mapping | ◐ Possible with JMX extension customization | ◐ Possible with custom JMX Exporter rules |
| Speculative retries | ✓ Native | ◐ Possible | ◐ Not documented out of the box | ◐ Not documented out of the box | ◐ Not documented out of the box |
| Storage layer | |||||
| Live SSTable count | ✓ Native | ◐ Possible | ◐ Possible via Datadog Cassandra Agent check | ◐ Possible via Dynatrace Cassandra JMX extension | ◐ Possible with custom JMX Exporter rules |
| SSTables read per query percentiles | ✓ Native All percentiles. |
◐ Possible | ◐ Possible with extra JMX mapping | ◐ Possible with JMX extension customization | ◐ Possible with custom JMX Exporter rules |
| Bloom filter disk size | ✓ Native | ◐ Possible | ◐ Possible via Datadog Cassandra Agent check | ◐ Possible via Dynatrace Cassandra JMX extension | ◐ Possible with custom JMX Exporter rules |
| Bloom filter false positive ratio | ✓ Native | ◐ Possible | ◐ Possible with extra JMX mapping | ◐ Possible with JMX extension customization | ◐ Possible with custom JMX Exporter rules |
| Max table partition size | ✓ Native | ◐ Possible | ◐ Not documented out of the box | ◐ Not documented out of the box | ◐ Not documented out of the box |
| Mean partition size | ✓ Native | ◐ Possible | ◐ Not documented out of the box | ◐ Not documented out of the box | ◐ Not documented out of the box |
| Threadpools | |||||
| Cassandra threadpool health | ✓ Native Active, pending, completed, currently blocked, and all-time blocked metrics across Cassandra threadpools. |
◐ Possible Available through JMX if you model and visualize it yourself. |
◐ Possible via Datadog Cassandra Agent check | ◐ Possible via Dynatrace Cassandra JMX extension | ◐ Possible with custom JMX Exporter rules |
The point of this table is not that the other platforms can never ingest these metrics. Most of them can ingest at least part of the underlying JMX surface. The practical difference is that AxonOps already models these as Cassandra metrics that are usable immediately, including percentile-heavy and consistency-level views. The other options usually require some combination of exporter rules, metric selection, field mapping, dashboard work, and alert engineering before the same data becomes operationally useful.
What this metric depth does to SaaS cost
This is also where the commercial model starts to matter. Generic SaaS observability tools can usually be pushed deeper into Cassandra, but deep per-table telemetry is exactly the point where their default scope stops and billable expansion begins.
Using the actual table-level inventory above, 100 tables and the 24 Cassandra threadpools you listed with ActiveTasks, PendingTasks, CompletedTasks, CurrentlyBlockedTasks, and TotalBlockedTasks produce this footprint per node.
- Table-level metrics across 100 tables:
100 × 67 = 6,700metric series per node. - Threadpool metrics:
24 × 5 = 120metric series per node. - Base table-level footprint:
6,700 + 120 = 6,820metric series per node. - If you also break coordinator read, range-read, and write throughput and latency out across
8common consistency levels, add100 × 8 × 24 = 19,200more metric series per node. - Estimated total with consistency-level coverage:
6,820 + 19,200 = 26,020metric series per node.
Datadog is the easiest place to turn that into a public-cost estimate because it publishes both the Cassandra check limit and a public custom-metric price list. The documented 350-metric default for the Cassandra Agent check is not close to this footprint. The 6,820-series base estimate is about 19.5x higher than Datadog’s standard check limit. The 26,020-series estimate with consistency-level coverage is about 74.3x higher.
Datadog’s billing documentation says Infrastructure Pro includes 100 indexed custom metrics per host, and Datadog’s public pricing list shows custom metrics at 336** per node per month in indexed custom-metric overage before the base host fee. A node carrying the richer 26,020-series footprint lands at roughly 2,016 to $7,776 per month in Datadog custom-metric overage alone.
Grafana Cloud publishes a simpler metrics model, but the public Pro pricing baseline assumes 1 data point per minute, which is effectively 60-second resolution. Its Pro plan includes 10k active series at that baseline and then charges 19 monthly platform fee. On that basis, a six-node Cassandra cluster at the 6,820-series-per-node footprint lands at about 40,920 active series, or roughly 969 per month for metrics.
At a 5-second scrape interval, Grafana Cloud billing moves to 12 DPM, so the six-node cluster totals become much more expensive:
40,920active series across the 6-node cluster: roughly $3,146/month for metrics.156,120active series across the 6-node cluster: roughly $12,131/month for metrics.
That is before logs, users, and any additional Grafana Cloud services.
The other SaaS platforms expose the same pattern through different charging models. Dynatrace documents 28 default Cassandra JMX metrics per process and a 5,000-metric limit per JMX extension. Grafana Cloud documents a Cassandra integration built on JMX Exporter plus active-series pricing. The commercial model is different, but the engineering reality is the same: once you insist on deep Cassandra table visibility, the default footprint is gone, the Cassandra JVM starts paying a heavier CPU price for those JMX scrapes, and the monitoring platform starts charging you for the privilege. The underlying overhead problem is covered in more detail in Monitoring Cassandra: The Cost of Collecting Metrics.
Alert rule features
| Rule capability | AxonOps | Self-managed stack | Datadog | Dynatrace | Grafana Cloud |
|---|---|---|---|---|---|
| Metric threshold rules | ✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes |
| Severity and scope controls | ✓ Native Documented around cluster, datacenter, metric type, and severity. |
◐ Label-driven Powerful, but only if your labels are consistent. |
◐ Tag-driven | ◐ Entity and tag-driven | ◐ Label-driven Powerful once labels and rule groups are modeled well. |
| Log-based alerting | ✓ Yes Cassandra log rules in the same platform as metrics and service checks. |
✓ Yes Loki supports alerting, but it is another component to own. |
✓ Yes | ◐ Log processing path Achievable through log processing and metric events, but not as direct. |
✓ Yes Loki and Grafana Alerting support it, but it still depends on the log labels and queries you maintain. |
| No-data or loss-of-signal detection | ✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes | ✓ Yes |
| Anomaly or baseline-based rules | ◐ Focused on operational thresholds and service checks | ◐ Custom Possible, but usually requires extra recording rules or external logic. |
✓ Yes | ✓ Yes | ◐ Dynamic thresholds Available, but you still define the Cassandra rules and labels yourself. |
| Cassandra operational rules | ✓ Yes Backups, repairs, nodetool tasks, service checks, and security events. |
✗ Not documented out of the box | ✗ Not documented out of the box | ✗ Not documented out of the box | ✗ Not documented out of the box |
| Rule automation | ✓ Yes Terraform can manage AxonOps monitoring and alerting configuration across rules, routes, service checks, and related platform settings. |
✓ Yes Everything is configuration, but you own the full implementation. |
✓ Yes | ✓ Yes | ✓ Yes Terraform provisioning is documented for Grafana rule groups, contact points, and notification policies. |
| Time to first useful Cassandra alert set | Fast | Slow | Medium | Medium | Medium |
This is where the shape of the market becomes clear. Datadog, Dynatrace, and Grafana Cloud all have capable alerting engines. Grafana Cloud is the most open of the three because it stays close to Prometheus and Loki, but it still does not give you Cassandra-native alert coverage for repairs, backups, nodetool workflows, or Cassandra service checks out of the box. The self-managed stack can eventually cover much of this, but only if you are willing to design and maintain the full rule set yourself.
AxonOps wins this section for a different reason. It is opinionated in the right place. Instead of forcing Cassandra teams to translate every operational concept into raw metrics and labels, it already exposes the Cassandra domains that SREs and DBAs actually monitor day to day.
Alert routing features
| Routing capability | AxonOps | Self-managed stack | Datadog | Dynatrace | Grafana Cloud |
|---|---|---|---|---|---|
| Built-in delivery channels | ✓ Broad Slack, Microsoft Teams, ServiceNow, PagerDuty, OpsGenie, SMTP, email, and webhook are documented. |
✓ Broad Alertmanager and Grafana cover the common channels, though across separate components. |
✓ Broad | ✓ Broad | ✓ Broad |
| Routing policy filters | ✓ Yes | ✓ Yes Alertmanager and Grafana are strong here. |
✓ Yes | ✓ Yes | ✓ Yes Notification policies and label matchers are strong here. |
| Routing by Cassandra context | ✓ Native Route by metric domain, cluster, datacenter, node, and severity. |
◐ Custom Possible if labels are carefully designed and kept consistent. |
◐ Tag and team routing Usually tag and team based rather than Cassandra-domain aware. |
◐ Entity and tag routing Entity and tag based rather than Cassandra-domain aware. |
◐ Label and policy routing Possible with notification policies and label matchers, but not Cassandra-domain aware by default. |
| Metrics and logs routed in one model | ✓ Yes | ◐ Shared ownership model Possible, but shared ownership between Prometheus, Alertmanager, Grafana, and Loki matters. |
✓ Yes | ✓ Yes | ✓ Yes |
| Repairs, backups, service checks, and alerts share one routing model | ✓ Yes Repairs, backups, service checks, and security events use the same routing rules as metrics and logs. |
✗ No | ✗ No Custom events can be created, but Cassandra operations are not native objects. |
✗ No | ✗ No |
| On-call handoff quality for Cassandra incidents | High Routing context already matches Cassandra ownership boundaries. |
Variable Depends on how well labels, dashboards, and runbooks were designed. |
Good | Good | Variable Depends on label hygiene, dashboard design, and the runbooks around your Grafana Cloud stack. |
Alert routing is where many Cassandra teams quietly lose time. The issue is not whether a platform can send to Slack or PagerDuty. Most can. The issue is whether the routing model matches how Cassandra ownership works in real environments. If an alert belongs to a specific cluster, datacenter, or operational domain such as repair or backup, the system should already understand that. AxonOps does. The DIY stack can get there with disciplined label design. The general SaaS platforms can usually approximate it with tags and workflows. None of those options is as direct.
What this means for each option
Self-managed stack
The self-managed JMX Exporter, node_exporter, Prometheus, Grafana, and Loki route fits teams that already run their own observability stack well and want full control. You get flexibility, but you also own exporter rules, dashboards, retention, Alertmanager, Loki, upgrades, and operational consistency.
Managed observability platforms
Datadog and Dynatrace fit teams standardizing on one broad observability platform across many systems. Grafana Cloud fits teams that want a managed Prometheus, Grafana, and Loki stack. Cassandra is visible in all three, but deep table metrics, Cassandra-specific routing, repair state, backup state, and configuration visibility still require extra engineering, extra scope, or extra spend.
AxonOps
The vendor docs make that clear. Datadog documents a 350-metric default for its Cassandra Agent check. Dynatrace uses a Cassandra JMX extension model. Grafana Cloud documents a Cassandra integration built on JMX Exporter, Grafana Alloy, 8 alerts, and 3 dashboards. AxonOps fits teams that need Cassandra itself to be first-class, with metrics, logs, service checks, configuration visibility, repairs, backups, security events, PromQL-compatible querying, and routing already aligned to Cassandra operations. It also keeps you on open Apache Cassandra.
Conclusions
Generic monitoring tools can monitor Cassandra, but they do not usually provide the granularity and breadth of metrics needed to diagnose Cassandra issues properly. Once you need deep table metrics, threadpool visibility, consistency-level context, and high-resolution collection at the same time, those platforms start forcing trade-offs in coverage, cost, or Cassandra JVM overhead.
AxonOps is stronger because it is not only a metrics and logs surface. It also brings together service checks, configuration visibility, repair state, backup state, security events, PromQL-compatible access, routing that already matches how Cassandra teams operate the database, and Terraform-driven control over monitoring and alerting configuration.
Our position is simple: AxonOps is the best-in-class Cassandra monitoring tool in this comparison. It gives engineers the deepest practical Cassandra visibility, broader operational insight around the database, and all of that for a fraction of the cost of Datadog and Grafana Cloud once you compare like for like on table-level metrics, threadpool coverage, consistency-level insight, and the wider operating context Cassandra teams actually need.
For the product detail behind that position, see AxonOps for Apache Cassandra monitoring.
If you want to talk through your current Cassandra monitoring setup, contact us. We can help you assess coverage gaps, overhead, and cost trade-offs against what AxonOps provides.