
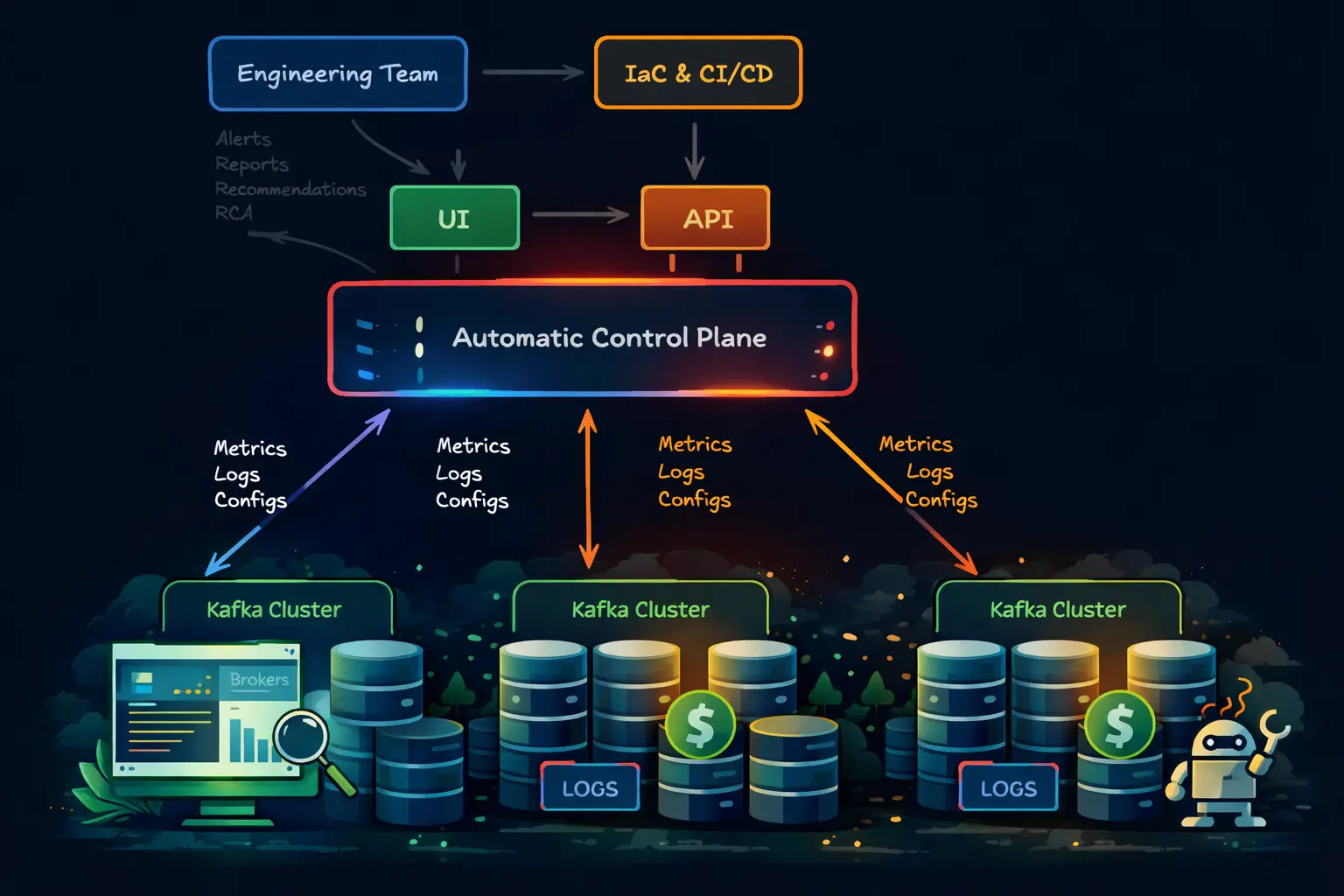
Teams in the middle
A large part of the Kafka community sits between two extremes. Enterprise operators have specialist teams and internal tooling. Smaller teams can survive with a few scripts and periodic manual checks. But teams running 5 to 30 brokers usually have neither option — the same engineers who manage Kafka are also responsible for databases, deployment pipelines, and incident response across other systems. Kafka is mission-critical, yet it competes for attention with everything else in production, so day-2 operations need to be structured and repeatable.
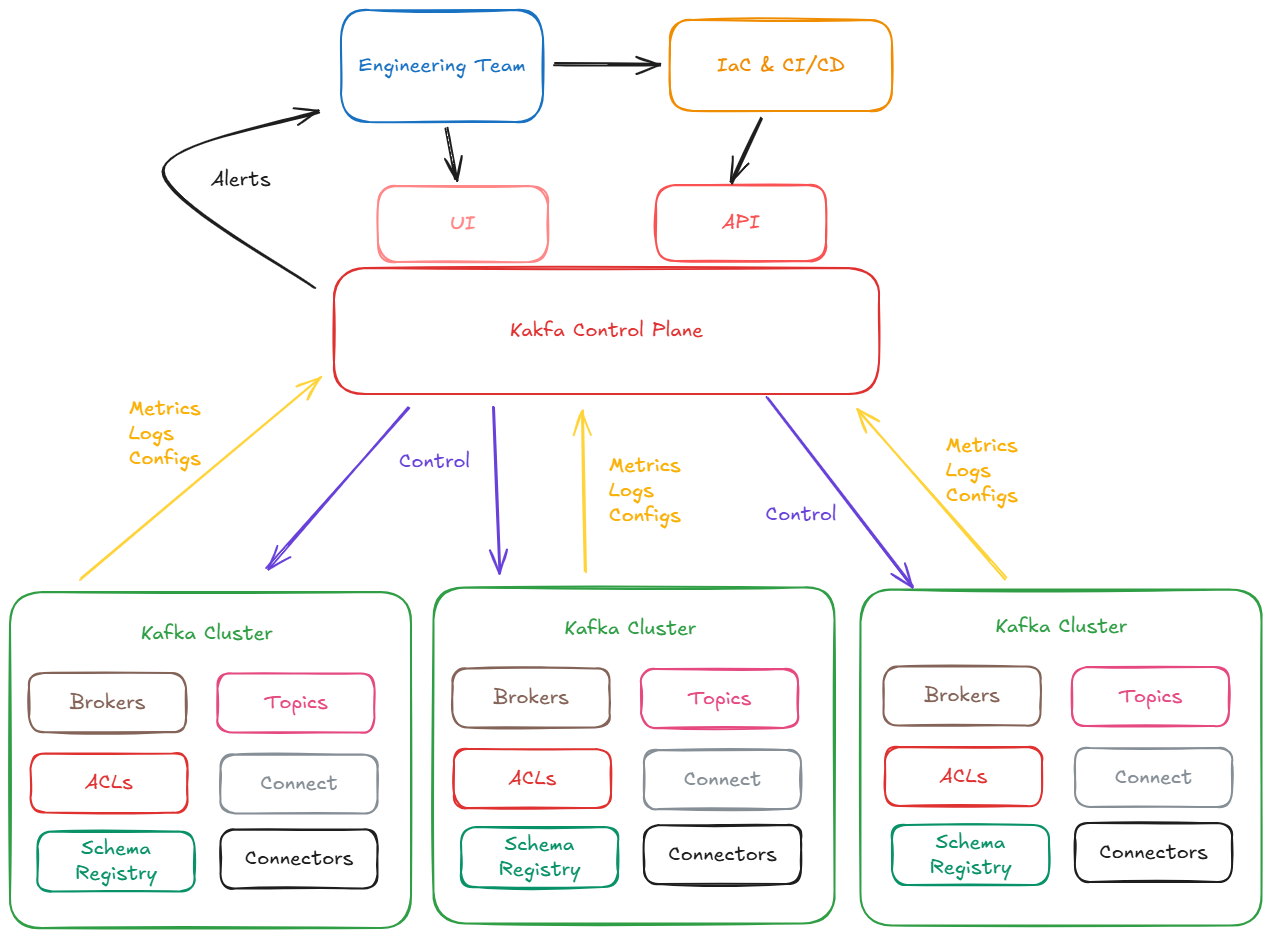
Cluster job scheduling and maintenance
Kafka clusters require regular operational tasks: rolling restarts for configuration changes or upgrades, partition reassignments, log directory migrations, and broker decommissions. Without a structured way to schedule and coordinate these jobs, teams fall back on ad-hoc scripts and manual sequencing across SSH sessions.
Rolling restarts are a good example. The sequence is straightforward — remove a broker from service, let leadership move, apply the change, bring the broker back, verify recovery, move to the next node — but maintaining confidence at each step while production traffic continues is where teams lose time. Across 15 to 20 brokers, that validation loop can consume hours:
# Check under-replicated partitions before restarting broker 3
kafka-topics.sh --bootstrap-server broker1:9092 \
--describe --under-replicated-partitions
# Verify ISR count matches replication factor
kafka-metadata.sh --snapshot /var/kafka-logs/__cluster_metadata-0/00000000000000000000.log \
--broker 3The same coordination overhead applies to other maintenance tasks. Partition reassignments need to be throttled and monitored. Broker decommissions require tracking replica movement across the cluster. Each of these jobs involves a check-execute-verify loop that is easy to get wrong under pressure.
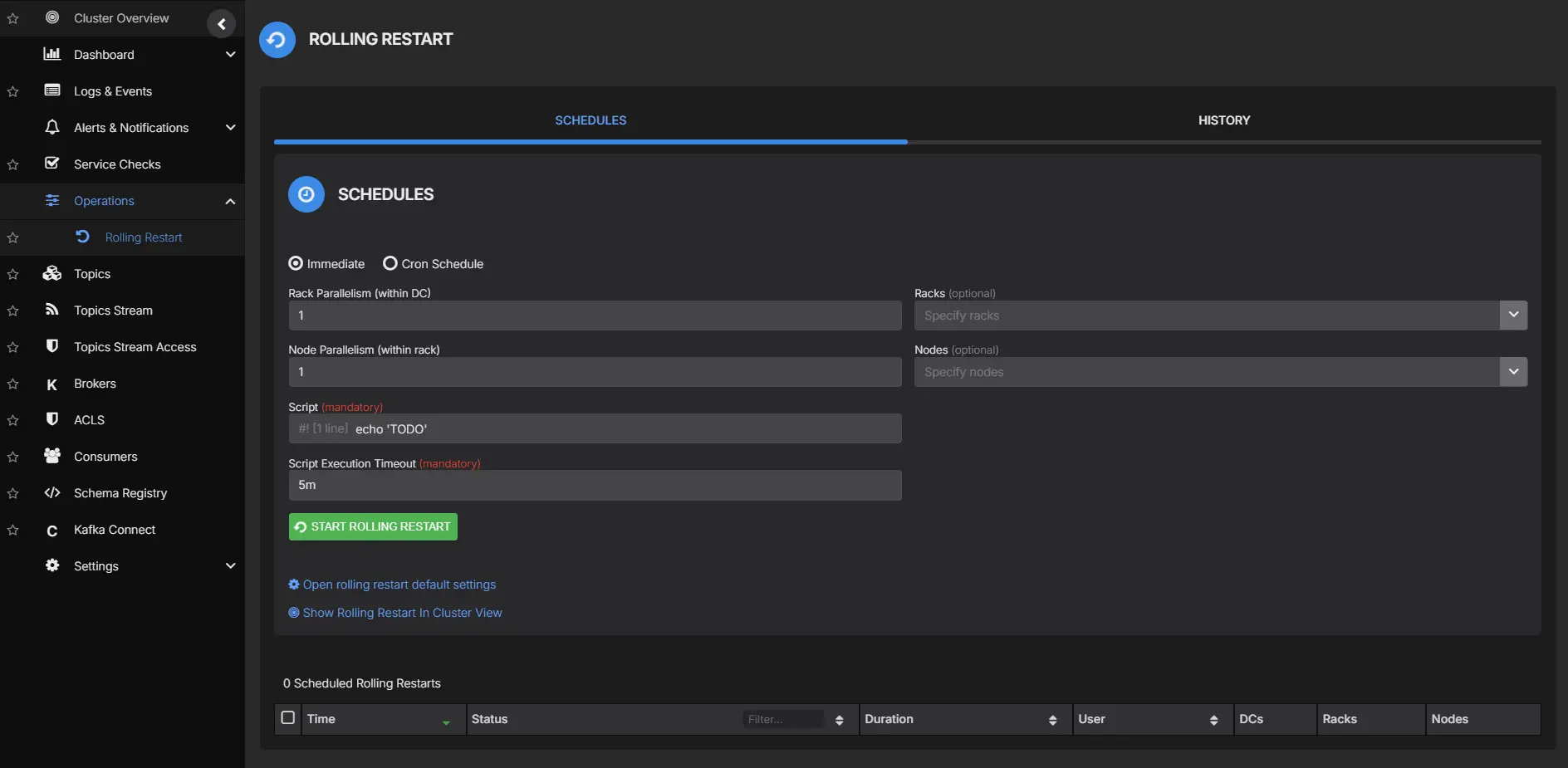
AxonOps provides a central surface for scheduling and tracking these cluster operations. For rolling restarts, broker health, replication status, and under-replicated partitions are visible in one view so teams can validate each transition without switching between terminals. An alert on under-replicated partitions can guard against proceeding too early:
# PromQL-style alert: catch under-replicated partitions during maintenance
kafka_server_replica_manager_under_replicated_partitions > 0
for: 2mTopic lifecycle management
Topic administration is often treated as occasional platform work, but on active systems it becomes daily operations. Teams create new topics, tune partitions and replication, adjust retention and compaction, and retire stale assets that are no longer consumed.
The Kafka CLI remains powerful, but repetitive administration through shell workflows is costly when the work scales up. Even straightforward changes require careful command construction and environment-specific authentication context:
# Adjust retention on a high-volume topic
kafka-configs.sh --bootstrap-server broker1:9092 \
--entity-type topics --entity-name events.clickstream \
--alter --add-config retention.ms=259200000,retention.bytes=107374182400
# Check effective configuration afterwards
kafka-configs.sh --bootstrap-server broker1:9092 \
--entity-type topics --entity-name events.clickstream \
--describeComparing effective configuration across environments also becomes tedious when each cluster has its own broker defaults.
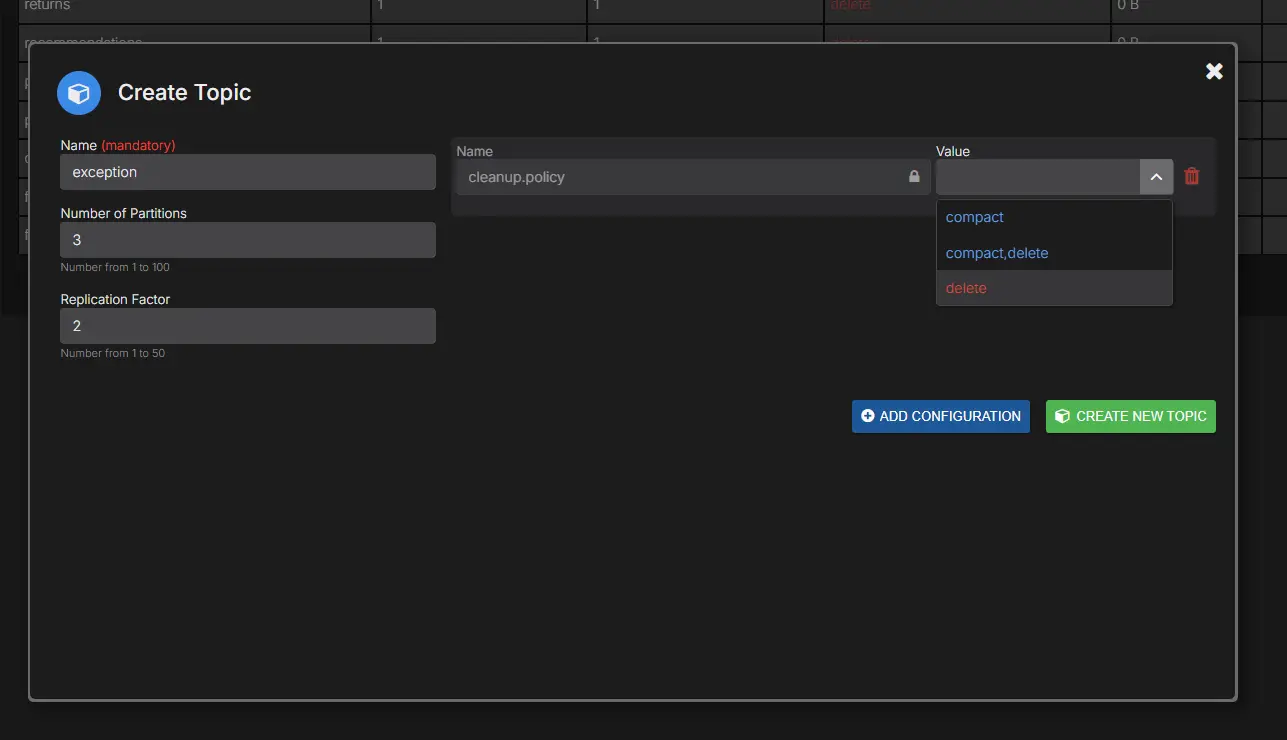
AxonOps provides a unified topic lifecycle surface for create, inspect, update, and retire tasks where operators can see explicit overrides alongside inherited broker defaults, inspect partition details, and review consumer relationships without stitching information from multiple tools.
ACL governance and audit readiness
ACL management follows a similar pattern. At small scale, permissions can stay simple and easy to reason about. In shared environments with many applications, ACLs become both a security boundary and an audit artifact.
Kafka ACLs are flexible, but visibility is usually the hard part. CLI-only workflows make it difficult to review principals, resources, and authorization scope in one place:
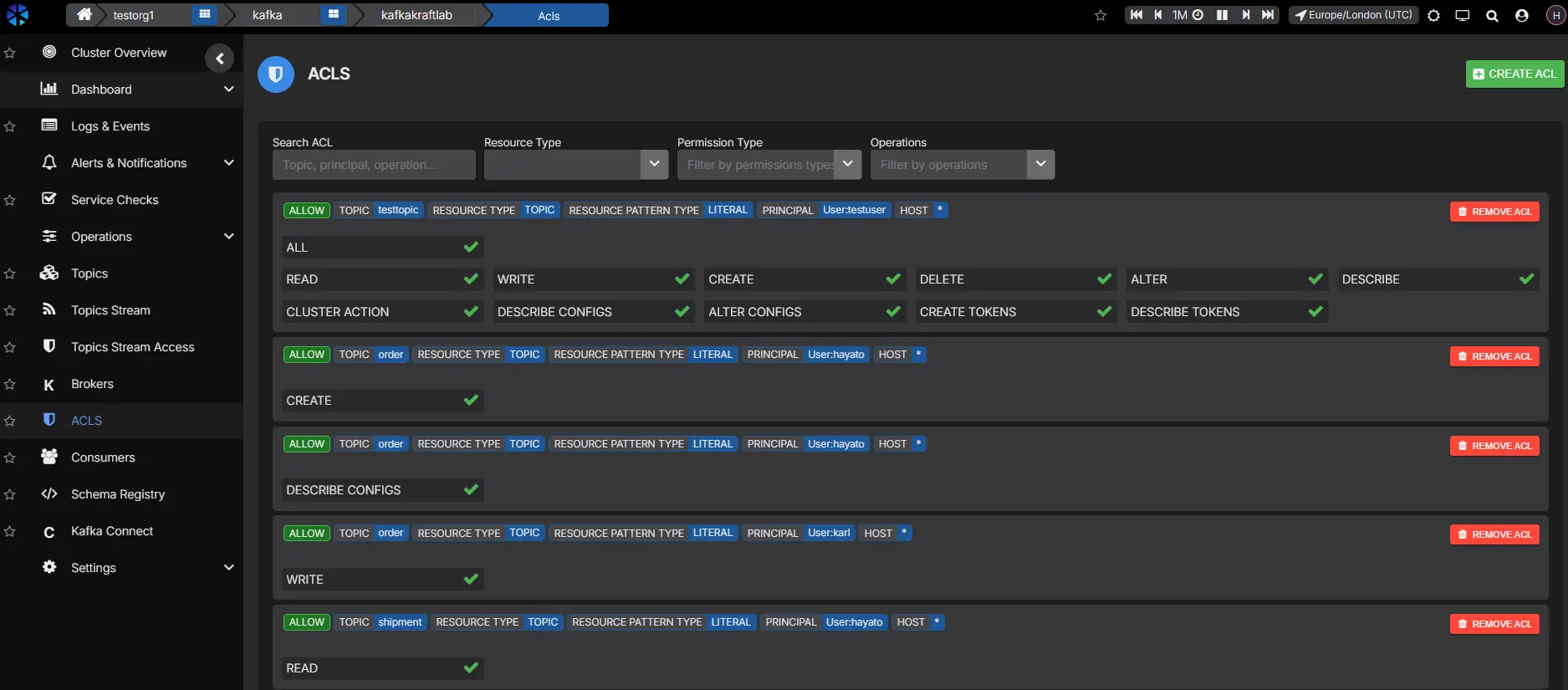
Historical context is also hard to reconstruct during incident review or compliance checks. AxonOps gives teams searchable ACL views with principal context and change history so access reviews become faster and more defensible.
API-first operations with CI/CD and IaC
A UI is useful for ad-hoc changes, but repeatable operations depend on automation. For teams without a dedicated platform group, automation is how you protect engineer time for decisions that need judgment.
AxonOps exposes a REST API for the same operational domains available in the UI, including topic configuration, ACL management, cluster inspection, and metrics access. For teams using Terraform, the AxonOps Terraform provider lets you manage Kafka topics as infrastructure resources directly:
# Topic for event streaming
resource "axonops_kafka_topic" "events" {
name = "user-events"
partitions = 12
replication_factor = 3
cluster_name = "my-kafka-cluster"
config = {
cleanup_policy = "delete"
retention_ms = "259200000" # 3 days
delete_retention_ms = "86400000" # 1 day
max_message_bytes = "1048576" # 1MB
}
}
# Compacted topic for state storage
resource "axonops_kafka_topic" "state_store" {
name = "user-profiles"
partitions = 6
replication_factor = 3
cluster_name = "my-kafka-cluster"
config = {
cleanup_policy = "compact"
min_cleanable_dirty_ratio = "0.1"
segment_ms = "3600000" # 1 hour
}
}This keeps Kafka resource definitions in version control alongside compute and network infrastructure, reducing ticket-driven workflows. The same API also integrates into CI/CD pipelines for teams that prefer scripted provisioning over Terraform.
Alerting for Kafka workloads
Most teams already have alerting systems. The issue is signal quality. Generic thresholds often create noise during expected traffic variation, then miss conditions that actually matter. A consumer lag value that is acceptable for batch traffic can be critical for low-latency stream processing, and threshold behavior changes by topic, consumer group, and traffic profile.
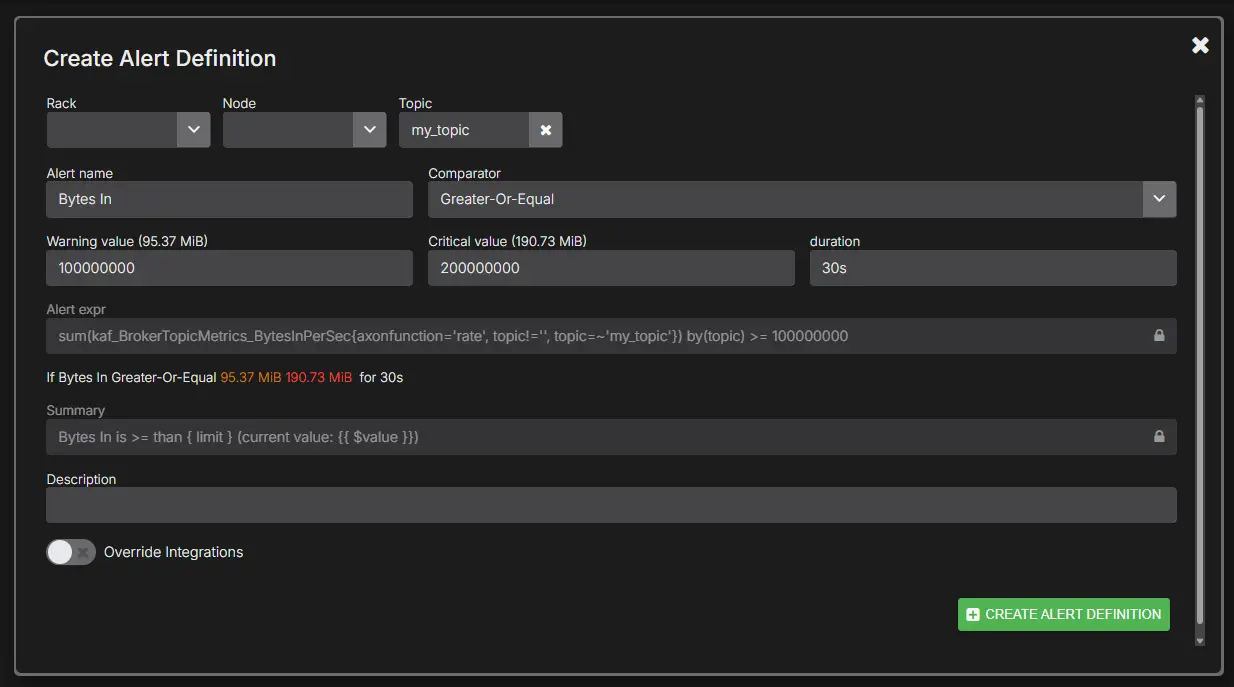
AxonOps supports Kafka-focused alerting with routing into PagerDuty, Slack, Microsoft Teams, email, and webhooks. Duration qualifiers and scoped thresholds help reduce false positives:
Kafka on Kubernetes with Strimzi
Many mid-size teams run Kafka on Kubernetes using Strimzi, which handles broker lifecycle through custom resources. Instead of scripting broker provisioning, upgrades, and scaling, teams declare the desired state in a Kafka CR and the Strimzi operator reconciles it. This removes a significant amount of manual coordination, but it also shifts the operational surface in ways that matter for day-2 work.
Strimzi manages the broker process lifecycle, but it does not provide deep operational visibility into what the brokers are doing. Partition health, consumer lag trends, replication status, and storage growth still need a dedicated monitoring layer. Teams that rely solely on kubectl logs and Prometheus scrapers end up building the same fragmented tooling they had before Kubernetes.
AxonOps serves as the control plane on top of Strimzi-managed clusters, handling the same operational domains it covers on VM-based deployments: topic lifecycle management, ACL governance, alerting, consumer group monitoring, and cluster-wide observability. Strimzi owns the broker process lifecycle, but AxonOps manages the operational layer above it. The AxonOps agent deploys as a sidecar or DaemonSet alongside the Strimzi-managed brokers, so there is no conflict with the operator’s reconciliation loop.
This means teams get a single control plane regardless of deployment model. Whether Kafka runs on bare metal, VMs, or Kubernetes with Strimzi, topic creation, ACL changes, alert configuration, and operational dashboards all live in the same place. Teams do not need separate tooling or workflows for their Kubernetes clusters.
The combination also enables practical auto-remediation patterns. AxonOps can detect conditions like sustained consumer lag, under-replicated partitions, or disk pressure and fire webhooks that trigger Strimzi-side actions — scaling up replicas, triggering a rolling update, or adjusting resource limits through the Kafka CR. Strimzi handles the safe execution while AxonOps provides the detection and decision layer.
Summary
Running Kafka well without a dedicated platform team is mostly a workflow problem. The technology is understood; what teams need is a control plane that turns routine operational work into repeatable practice and keeps the right signals visible during change and incident response. AxonOps provides unified observability, targeted alert routing, topic and ACL operations, and API-first integration into existing delivery systems for teams that run Kafka alongside the rest of their production estate.